ナレッジの検索設定
検索結果の確認
ナレッジデータストア上部に設置された「検索バー」からは、登録されたデータに対して検索をかけることができます。

検索を行うと、スコアの高い順にデータが表示されます。
スコアの定義について
ナレッジデータストアのスコアは、クエリーに対するデータの「類似度」です。
1に近いほど、類似性の高いデータだとみなされています。
スコアの算出方法
スコアは大きく下記の2つによって決定されます。
① 検索クエリーとEmbeddingされたベクトルの類似度
② ラベルとクエリーの類似度
比重は① >>> ②です。
実際の検索時の挙動
RAGの仕組みに乗っ取り、会話のラリーが行われるたびに検索が行われます。
検索結果の上位から本文を取得し、プロンプトに追加されます。
類似度の高いデータが多い場合は、上からプロンプト文字数の上限に達するまで文章をプロンプトに追加します。 (上限の文字数は2025年1月時点では非公開です。)
類似度の高いデータが多くない場合は、Score 0.7以上を目安に、プロンプトに挿入されます。
検索結果と会話の精度をテストする
エージェントと会話を行うと、会話の履歴のレポートに「クエリー」が出力されます。
実際に会話で生成されたクエリーが確認できます。
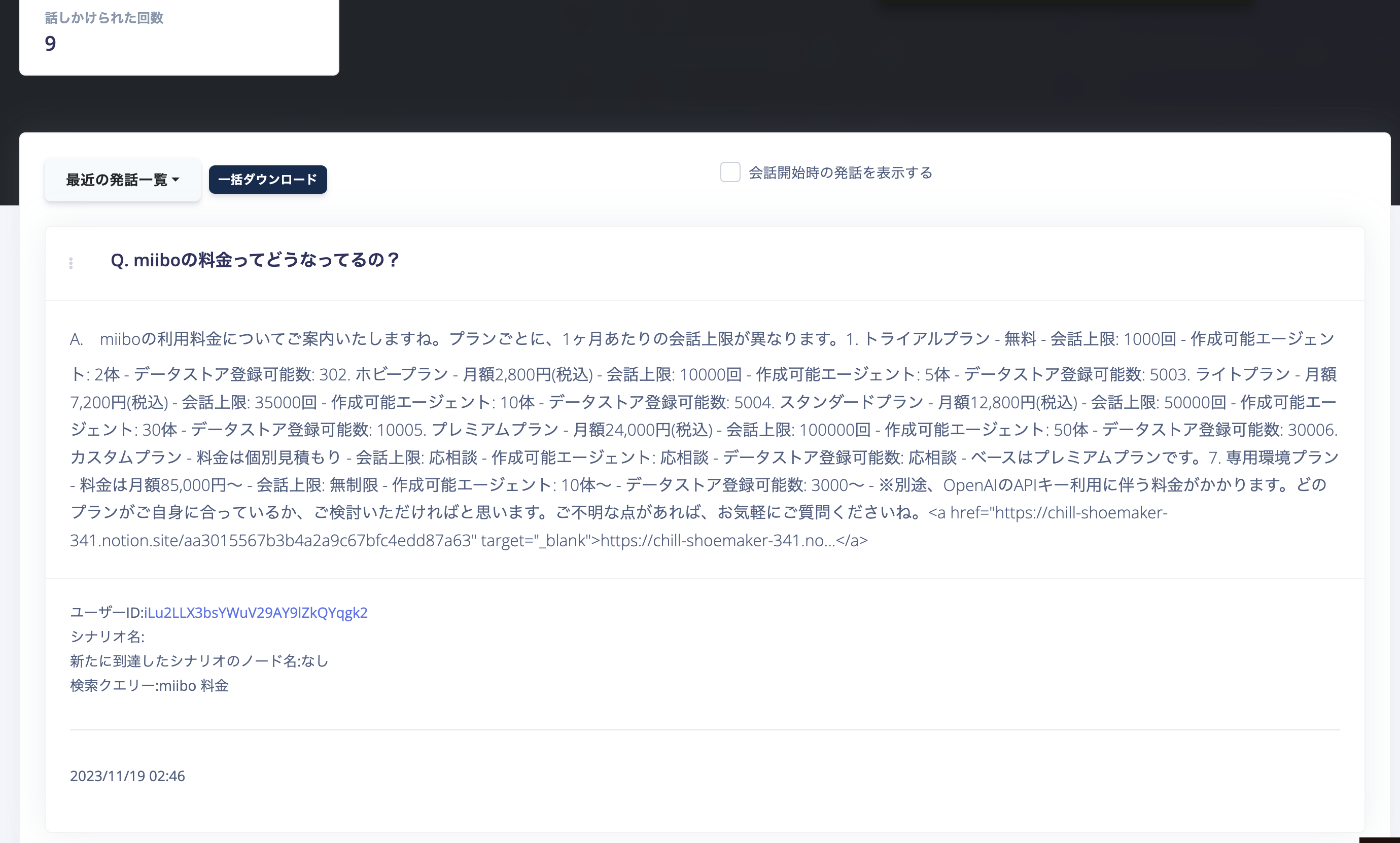
実際に生成されたクエリーをナレッジデータストアで検索してみることで、どのような情報が上位にマッチしていたのかを確認できます。この確認を行い、想定されるデータが上位に来ない場合は、本文を編集するなどして、チューニングを行ってください。
チャンクの制御
ナレッジデータストアに格納されるテキストは、およそ「1000文字」の塊に分けて処理されます。この塊をチャンク(CHUNK)と呼びます。1000文字を超えるテキスト自動的にチャンク分けが行われます。この区切りはシステムが自動的に判定しますが、文章の区切りが不適切な場合、RAGの精度を悪化させる可能性があります。
miiboでは、チャンクの位置を明示的に指定することができます。[CHUNK]という表記をナレッジデータストアに登録するテキストに含めることで、その位置でチャンクを行うようになります。
データの例:
会話型AIとは
本書では、人間が話しかけた言葉に対してAIが自動で応答するシステムを「会話型AI」と総称しています。似たような言葉として、「対話システム」「対話AI」「Conversational AI」といった表現があります。miiboは、人間の発話に対して自動応答するための様々機能を提供します。また、必ずしも話しかける側は人間であるとも限りません。AIがAIに話しかけて自動で業務を遂行することもあり得ます。会話型AIの扱う範囲は非常に広義になりつつあります。
代表的な活用例といえば「チャットボット」が有名です。カスタマーサポートの自動化など身の回りでチャットボットに触れる機会も増えてきているのではないでしょうか。
[CHUNK]
会話型AIの意義
会話型AI構築の方法をご紹介する前に、会話型AI開発の意義をご説明させてください。
会話型AIの一番重要なポイントは、「会話」は人類がもっとも長く慣れ親しんだ、「強力なコミュニケーションインターフェース」であるということです。人間は今まで様々な方法でコンピュータとコミュニケーションを図ってきました。キーボードやマウス、音声入力、スマートフォンのタッチ操作など、そのインターフェースは様々な変遷を辿ってきたわけです。
人間同士で古代から培ってきた「会話」というインターフェースは、利用者を限定せずシームレスに情報交換ができる洗練された方法です。それを人間とAI間に適用できることは、様々なIT技術を駆使したプロダクトが提供できる対象を拡大することにつながります。「デジタル・ディバイド」の解消もその恩恵の一つでしょう。AIの技術進歩は凄まじく、様々な問題を解決するポテンシャルを秘めています。しかし、コミュニケーションインターフェースが限定されると、せっかくのAI技術の恩恵も限定されてしまっていました。AI技術の恩恵を多くの人が享受しやすくなるためには、会話型AIの普及が不可欠です。
[CHUNK]
少々余談になりますが、本書で紹介する内容のアウトプットは「チャットボット」が大きな割合を占めます。それでも「チャットボット」ではなく「会話型AI」とわざわざ表記しているのは、ボイスボットやロボットなど文字コミュニケーションに閉じない範囲に応用できるという含みを持たせたい意図があります。チャットボットでの紹介が多くはなりますが、その他のユーザーインターフェースについても言及をしていきます。
2024年以降のAI領域は「マルチモーダルAI」の普及が加速します。チャットボットという既存のメッセージングUIにとらわれず、会話型AIの柔軟な活用に目を向けていくべきです。miiboも「マルチモーダルAI」の開発を行うプロダクトとしての進化を常に目指しています。※ [CHUNK]を挿入する場合も、文章は1000文字ごとに区切られます。
[CHUNK]を複数挿入する場合、[CHUNK]ごとの間の文字数が1000文字以上になると区切られてしまうため、1000文字を超えない分量で区切ることをおすすめします。
カスタムフィールド
※現在は、自由入力、URLからの入稿の場合のみ対応しています
カスタムフィールドには、データの属性情報やタグ、キーワードなどを含めることができます。(最大5件まで)
カスタムフィールドで追加したキーワードは、類似のキーワードがユーザーの発話に含まれるとScoreが上昇しやすくなります。また、カスタムフィールドに追加した情報は会話時のプロンプトにも含まれます。
ナレッジデータストアの文字数が多い場合、プロンプトには分割された文字列が入りますが、時に文字列が切れてしまい想定した情報が必ず前提データに入りきらない場合があります。Custom Fieldの内容は、ナレッジデータストアの本文の文字数に限らず、確実に前提データの上部に設置されます。必ず前提データに含め、プロンプトから指示をしたい場合等に有効です。
前提データの利用時のプロンプト:
前提データ1
ラベル:クイックリプライについて
参考URL: https://miibo.readme.io/docs/%E3%82%AF%E3%82%A4%E3%83%83%E3%82%AF%E3%83%AA%E3%83%97%E3%83%A9%E3%82%A4
カテゴリ:利用方法
機能名:クイックリプライ
本文: # クイックリプライとは [Skip link to クイックリプライとは](\#クイックリプライとは)
miiboでは、次にユーザーが発言したくなる可能性の高い発話候補のことを「クイックリプライ」と呼んでいます。
上記のように、プロンプトに採用される際に本文の上部にCustom Fieldの内容が格納されます。

カスタムフィールドの手入力
カスタムフィールドは上述の画面で入力する他、本文に下記のフォーマットで入力を行うことで登録が可能です。
(例)
@{custom_field_key=カテゴリ&custom_field_value=料金}上記のように、custom_field_keyとcustom_field_valueを指定することで、登録することができます。
検索採用数と閾値の設定
「プロンプト」内の「専門知識」にて、下記の2つの項目を設定可能です。
- 1度の会話で利用するデータの数
- 採用するスコアの閾値
1度の会話で利用するデータの数
1度の会話でナレッジデータストアの検索結果をいくつ採用するかを設定できます。
採用された検索結果は、会話のログの「この応答で使われた知識」でご確認いただけます。

採用するスコアのしきい値
採用する情報のスコアのしきい値を設定できます。しきい値を設定すると、そのスコアを超えた検索結果のみが採用されます。
検索方法の設定
同画面にて、ナレッジデータストアの検索方法は3つから選択できます。目的に応じて最適な方法を設定することで、より精度の高い情報検索を実現できます。
| 検索モード | 仕組み | 重視するポイント | 適したユースケース |
|---|---|---|---|
| ハイブリッド | 全文検索とベクトル検索をスコア順に採用 | 意味的類似性と単語一致をバランスよく考慮 | 一般的な問合せや様々な表現で来る質問 |
| ミックス | 全文検索とベクトル検索を交互に採用 | キーワードの正確性と意味の類似性の両方を均等に | 複合的な質問や多角的な情報提供が必要な場合 |
| キーワード検索(全文) | キーワードベースの検索 | 単語や語句の完全一致 | 製品名、型番、法令など固有名詞や専門用語を含む質問 |
検索方法の精度比較
| 検索モード | 検索精度のメリット | 検索精度のデメリット |
|---|---|---|
| ハイブリッド | • キーワード検索と意味的検索の両方の利点を活用 • 同義語や類似概念も検出可能 • 表現の違いを超えた検索が一定程度可能 • 精度(Precision)と再現率(Recall)のバランスが良い • 複数の検索基準による多面的な関連性評価 | • キーワード検索と意味検索の統合方法により精度が変動 • 両方の弱点を部分的に持ち込む可能性 • 統合アルゴリズムの調整が難しい • 異なる種類の関連性の重み付けが複雑 • 検索結果の一貫性確保が課題 |
| ミックス | • 最も高い意味的理解と関連性検出能力 • 相互フィードバックによる検索精度の向上 • 表現の違いに非常に強い • 暗黙的な関連性の検出に優れる • 検索結果が互いに補完し合う • 複雑な質問や曖昧な表現への対応力が高い | • 過剰な一般化によりノイズを拾う可能性 • 検索手法間の相互干渉による精度低下のリスク • チューニングが複雑で最適バランスの発見が難しい • 検索結果の説明可能性が低下 • 相互強化による誤った関連性の増幅リスク |
| キーワード検索(全文) | • キーワードの完全一致に非常に強い • 特定の専門用語や固有名詞の検索に優れる • クエリに含まれる単語が文書に存在する場合の検出率が高い • 否定語や限定語を含む複雑な条件検索が可能 • 特定のフレーズや正確な表現の検索に優れる | • 同義語や類似概念を検出できない • クエリと文書の表現が異なると検出不可 • 概念的な関連性の把握が困難 • コンテキスト理解が限定的 • 言い換えられた質問に弱い • 暗黙的な関連性を見つけられない |
全文検索モード
ベクトル検索を使わず、キーワードベースの全文検索のみを行うモードです。特定の単語や語句の完全一致を重視します。製品名や型番、法令など、固有名詞や専門用語を含む質問に対して効果を発揮します。
ユースケースと結果の変化
製品カタログや技術マニュアルなど、正確なキーワードマッチングが重要な場合に最適です。
「RAGの設定方法を教えてください」という質問では、検索クエリー生成プロンプトが「RAG,設定方法」などのクエリーを生成し、「RAG」「設定方法」が含まれる情報と周辺情報の文章を高精度で検索します。
miiboの利用規約や料金プランの参照など、特定の条件や名称が重要な場合、検索クエリーから得られたキーワードの完全一致による検索結果が優先されます。
同義語や類似表現よりも正確なキーワードマッチングが必要な場合、検索結果の的確性が向上します。
ミックス検索モード
ベクトル検索と全文検索の結果を交互に採用するモードです。両方の検索方法からバランスよく結果を取得します。キーワードの正確性と意味の類似性の両方を重視したい場合に効果的です。
ユースケースと結果の変化:
複合的な質問や幅広い情報提供が必要な場合に役立ちます。
「会話型AIの開発におけるベストプラクティス」のような質問では、検索クエリー生成プロンプトが「会話型AI,開発,ベストプラクティス」などのクエリーを生成し、「会話型AI」「開発」などのキーワードを含む情報と、「対話システム設計」など意味的に関連する情報を交互に取得します。
シナリオ対話設計やプロンプトの調整方法など、技術情報と概念説明の両方が必要な分野で特に効果を発揮します。検索クエリーから得られた結果をベクトル検索と全文検索で交互に採用することで、多角的な情報収集が可能になります。
偏りのない多角的な情報提供が可能になり、ユーザーの様々な観点からの質問に対応できます。
ハイブリッド検索モード(デフォルト)
ベクトル検索と全文検索を組み合わせ、スコアが高い順に検索結果を採用するモードです。意味的な類似性と単語の一致の両方を考慮した総合的な検索が可能です。多くのユースケースに適しており、バランスの取れた検索結果を提供します。
ユースケースと結果の変化:
一般的な問い合わせ対応で広く活用できます。
「ステート機能について教えて」といった質問には、「ステート」「機能」というキーワードを含む情報と、「ユーザー情報の保存方法」など意味的に関連する情報も検索結果に含まれます。
プロンプト設定やナレッジデータストアの活用など、様々な表現で問い合わせが来る場合に効果的です。
ミックス検索モードとハイブリッド検索モードの違い
ミックス検索モードとハイブリッド検索モードの違いは、データの採用の仕方が異なります。
ミックス検索モードは、全文検索とベクトル検索を交互に採用。つまり、どっちも必ず入った結果になります。
ハイブリッド検索モードは、全文検索とベクトル検索の両方で検索したScoreを加味して決定したデータを採用。つまり、両方を加味されたバランスの良い結果になります。
検索精度に関するユースケース別比較
検索精度に関するユースケース別比較です。検索モードを選択するときに参考にしてください。
事実検索(特定の情報を正確に探す場合)
- 全文検索: ★★★★★(正確なキーワードマッチングに最適)
- ミックス検索: ★★★☆☆(関連情報も多く含まれるため、特定情報の絞り込みが難しい場合も)
- ハイブリッド検索: ★★★★☆(キーワード部分が機能するが、過剰検出の可能性)
概念検索(テーマや概念に関連する情報を広く探す場合)
- 全文検索: ★★☆☆☆(関連キーワードを含まない情報は検出不可)
- ミックス検索: ★★★★★(最も広範な関連情報の検出が可能)
- ハイブリッド検索: ★★★★☆(意味的関連性も検出可能)
質問応答(質問の言い換えや異なる表現への対応)
- 全文検索: ★★☆☆☆(質問の表現に強く依存)
- ミックス検索: ★★★★★(最も多様な表現への対応力が高い)
- ハイブリッド検索: ★★★★☆(ある程度の言い換えに対応可能)
多言語検索(異なる言語間での検索)
- 全文検索: ★☆☆☆☆(基本的に同一言語内のみ)
- ミックス検索: ★★★★☆(相互強化により言語間の検索精度向上)
- ハイブリッド検索: ★★★☆☆(ベクトル部分で一部対応可能)
レアケース対応(一般的でない質問や特殊な表現)
- 全文検索: ★★☆☆☆(特殊な表現が一致する場合のみ)
- ミックス検索: ★★★★☆(複数の角度からのアプローチで対応力向上)
- ハイブリッド検索: ★★★☆☆(部分的な意味解釈により一部対応)
総合評価(検索精度の観点のみ)
- 全文検索: 特定キーワードの精確な検索に優れるが、意味的関連性や表現の違いへの対応に弱点
- ミックス検索: 最も高度な検索精度を提供するが、チューニングの複雑さと誤検出リスクのバランス調整が必要
- ハイブリッド検索: 精度と再現率のバランスが良く、多くのユースケースで十分な検索精度を提供
変更後の確認
検索モードの設定変更後は、テスト会話を行い、「この応答で使われた知識」で実際に採用された検索結果を確認することをお勧めします。特定の質問タイプでどのモードが最も効果的か評価し、必要に応じて調整してください。
ユーザーへの検索クエリ表示
「エージェント設定」->「詳細設定」->「専門知識」から設定が可能です。
ナレッジデータストアを検索する際、実際の検索キーワードをユーザーに表示する機能です。検索の透明性を向上させ、より具体的な質問を促すことができます。