ナレッジデータストアの利用
ナレッジデータストアとは
ナレッジデータストアは、miiboがサービス内で所有する、AIに与える専門知識を保持するためのデータベースです。 AIに与える情報をプールしておく、専門知識のバケツだとイメージしてください。
ナレッジデータストアに入れた情報は直ちにRAGの仕組みを適用し、AIの応答に専門知識を与えられるようになります。
ナレッジデータストアの特徴
ナレッジデータストアは下記の特徴を有しています。
- 登録した情報はEmbedding(ベクトル化)されること
- データの追加が手軽なこと
- 様々なデータフォーマットの追加に対応していること
- 検索結果を素早く確認できること
- API経由でデータ追加ができること
後の使い方紹介で上記の特徴はご体感いただけるかと思います。 一言で言うと、「超手軽なRAG環境」です。 RAG環境を自前で一から構築しようとすると、非常に高度な作業と手間が必要になります。 ナレッジデータストアは、直感的な作業で素早くRAG環境を構築できます。また、AIフレンドリーな高精度なデータ検索アルゴリズムを有しており、手軽な反面、高精度な応答生成を行うこともできます。
利用方法
ナレッジデータストアの作成
左メニューから「ナレッジ」を開きましょう。 初回のみ、「ナレッジデータストアを作成する」をクリックする必要があります。
データの追加
右下の「データを追加する」からデータの追加が可能です。 様々なフォーマットに対応しています。
| 入稿形式 | 容量・文字数制限 |
|---|---|
自由入力(テキスト) |
最大 50,000文字 |
URL |
URL最大 9,994文字 |
PDFファイル |
最大1,000MB |
テキストファイル |
最大1,000MB |
Notionページ |
Page ID 9,994文字 |
Excelファイル |
最大1,000MB |
Wordファイル |
最大1,000MB |
Powerpointファイル |
最大1,000MB |
Jsonファイル |
最大1,000MB |
マークダウン |
最大50,000文字 |
CSV形式* |
最大50,000文字 |
自由入力
自由にテキストを入力できます。ラベル、URL(任意)、本文、カスタムフィールド(任意)を設定しましょう。
指定された文字数(上限50000文字)の中で、データの本文を入力します。フォーマットは自由です。フォーマットは自由ですが、下記の方針に従うと応答の精度が安定します。
- 1つのデータ入稿に複数の話題を含めない
- 全てのデータのフォーマットに統一感をもたせる
データ本文の例1
miiboの料金プラン
miiboの初期利用時は、どなたでも「無料」でお試し利用が可能な「トライアルプラン」が適用されています。
また、プランごとに、月あたりの会話回数の上限が設定されており、それを超えた場合は、上位のプランの導入をご検討ください。
各料金プランの詳細は、こちらのページをご確認ください。データ本文の例2
質問: miiboの料金プランを教えて下さい。
回答:
miiboの初期利用時は、どなたでも「無料」でお試し利用が可能な「トライアルプラン」が適用されています。
また、プランごとに、月あたりの会話回数の上限が設定されており、それを超えた場合は、上位のプランの導入をご検討ください。
各料金プランの詳細は、こちらのページをご確認ください。URLを指定してデータを追加
指定したURLから情報を読み込み、ナレッジデータストアに読み込みます。URLは複数読み込めます。
留意事項
- Webページの構造によっては、正常に読み込めない場合があります
- ログイン等の認証が必要なWebページは読み込むことができません
- 手動で入稿するのに比べ、検索精度が落ちる可能性があります
- 本文が25000文字以上ある場合は、それ以降の文字列が無視されます
- 子ページのURLを抽出する場合、データ登録可能数以上のページはスキップされます。
例えば、NotionやSTUDIOで作成したWebページが正常に読み込めない場合があります。
「URL先の子階層も一緒に登録する」について
「URL先の子階層も一緒に登録する」を有効にした場合、指定した階層レベルに応じてそのページ内に貼られているリンク先も連鎖的に読み込まれます。 階層構造は以下のようになります。
- 0階層: 指定したURL
- 1階層: 0階層のページ内に貼られているリンク先
- 2階層以降: 前の階層のページ内に貼られているリンク先
外部サイトへのリンクも読み込み対象となるため、意図しないページが取り込まれる場合があります。 特定のページのみ取得したい場合は、「サイトマップからURLを抽出する」を利用するか、指定する子階層のURLをそれぞれ登録してください。
ファイルのインポート
フリーフォーマットの下記の拡張子のファイルを読み込むことができます。
- .txt
- .xlsx
- .docx
- .pptx
- .json
文字数とファイル容量には上限があります。
文字数:20万文字まで ファイル容量: 1GBまで ※ 今後、変更の可能性があります。
指定の形式のcsv形式でインポート
指定された形式のcsvファイルをインポートできます。
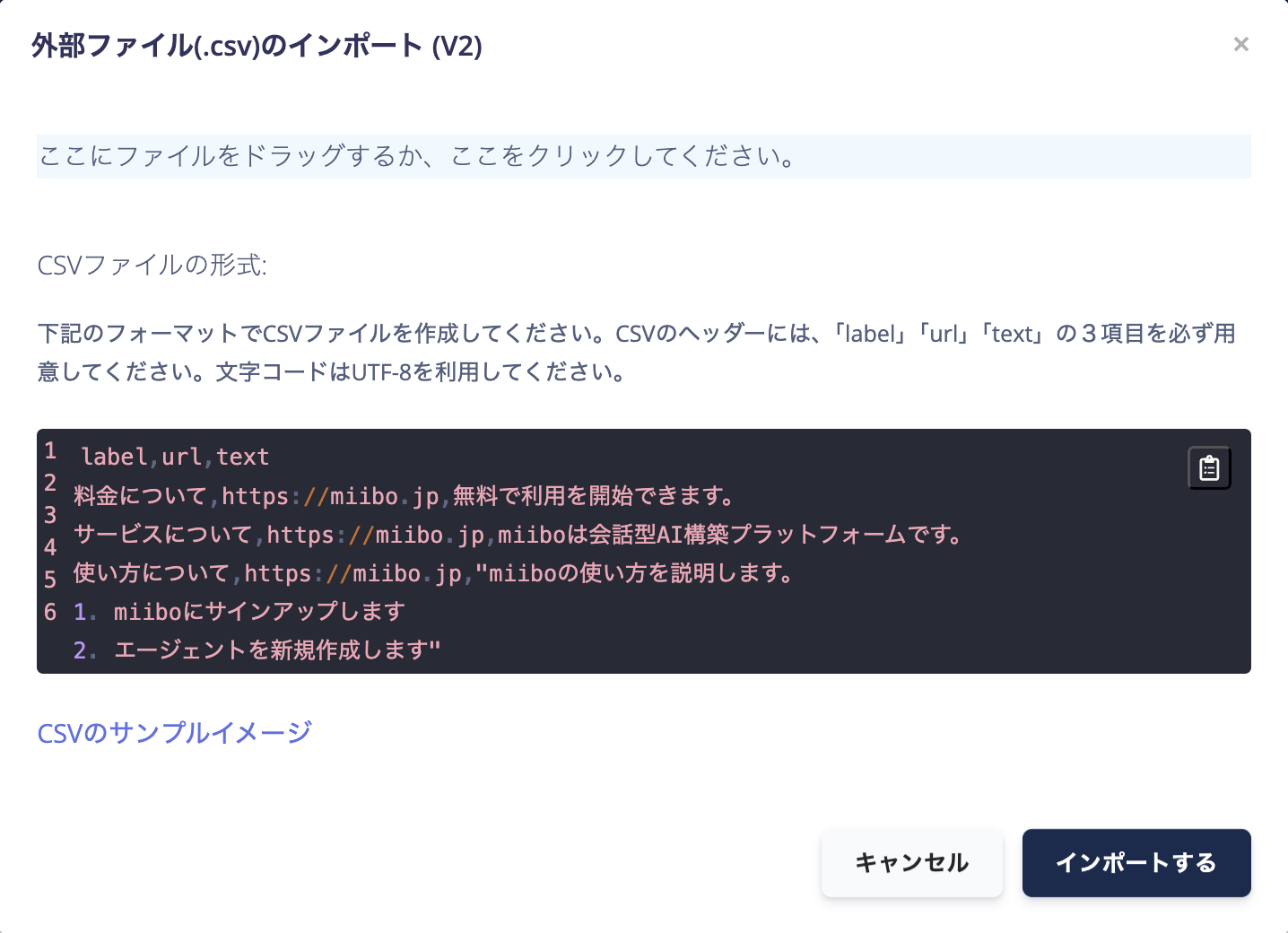
csvファイルのフォーマット
label,url,text
料金について,https://miibo.jp,無料で利用を開始できます。
サービスについて,https://miibo.jp,miiboは会話型AI構築プラットフォームです。
使い方について,https://miibo.jp,"miiboの使い方を説明します。
1. miiboにサインアップします
2. エージェントを新規作成します"
CSVのヘッダーには、「label」「url」「text」の3項目を必ず用意してください。 ※文字コードはUTF-8を利用してください。
miiboでエクスポートしたJSONファイルのインポート
指定されたフォーマットのJsonファイルをインポートできます。
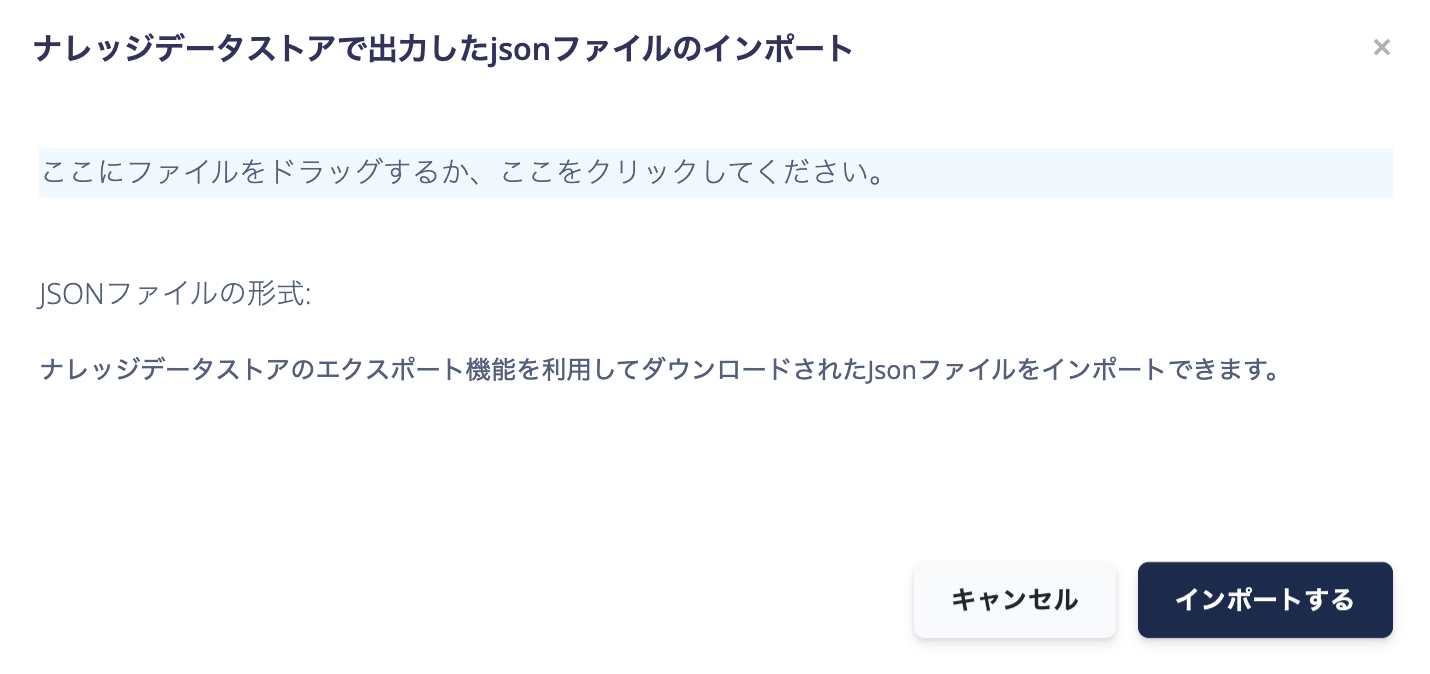
フォーマット指定のJsonファイルのインポートは、他のナレッジデータストアからエクスポートされたデータをインポートするために利用します。
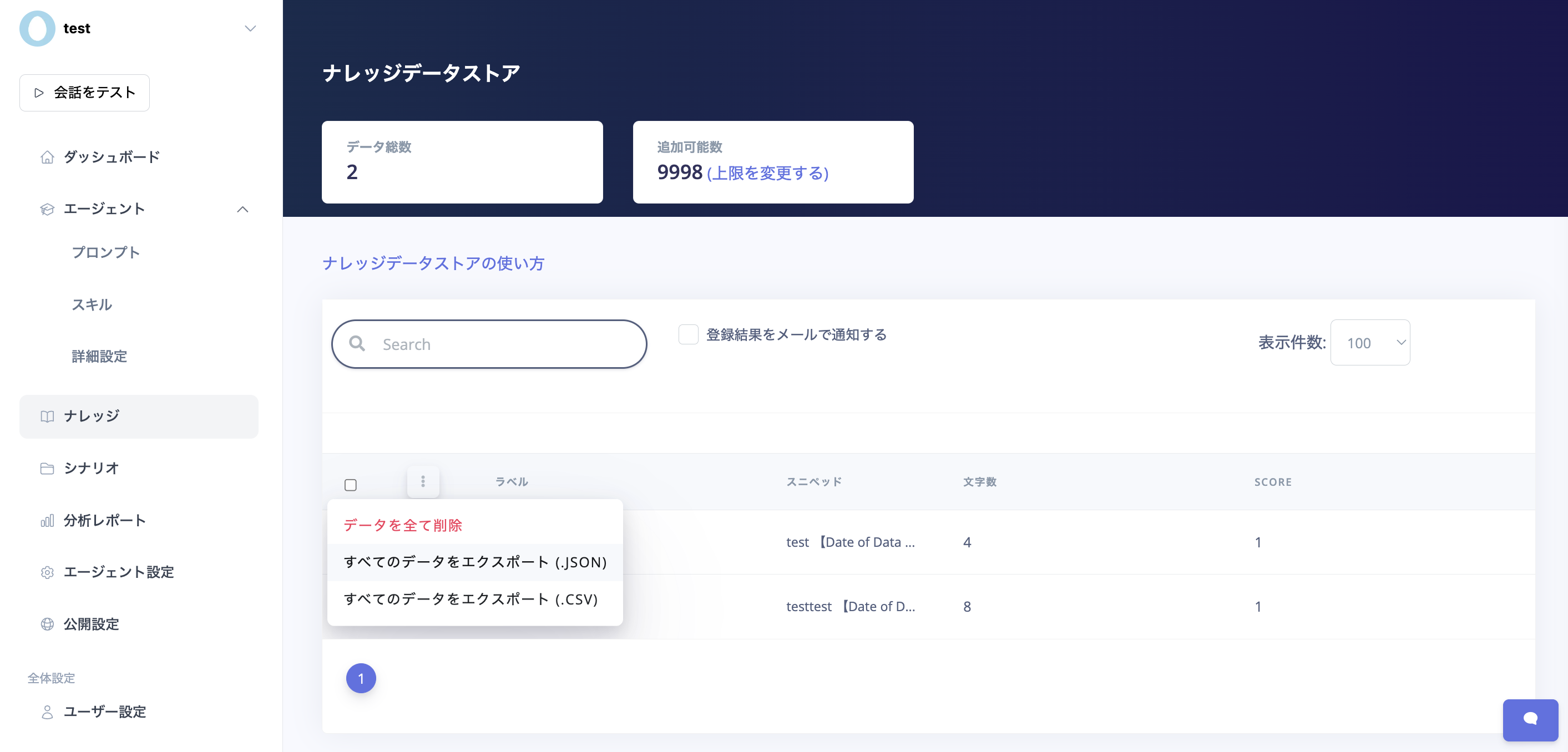
この「すべてのデータをエクスポート」ボタンで、ナレッジデータストアのデータをJson形式でエクスポートできます。(バックアップやエージェント間のデータ移行にご活用いただけます。)
Notionページからデータを入稿する
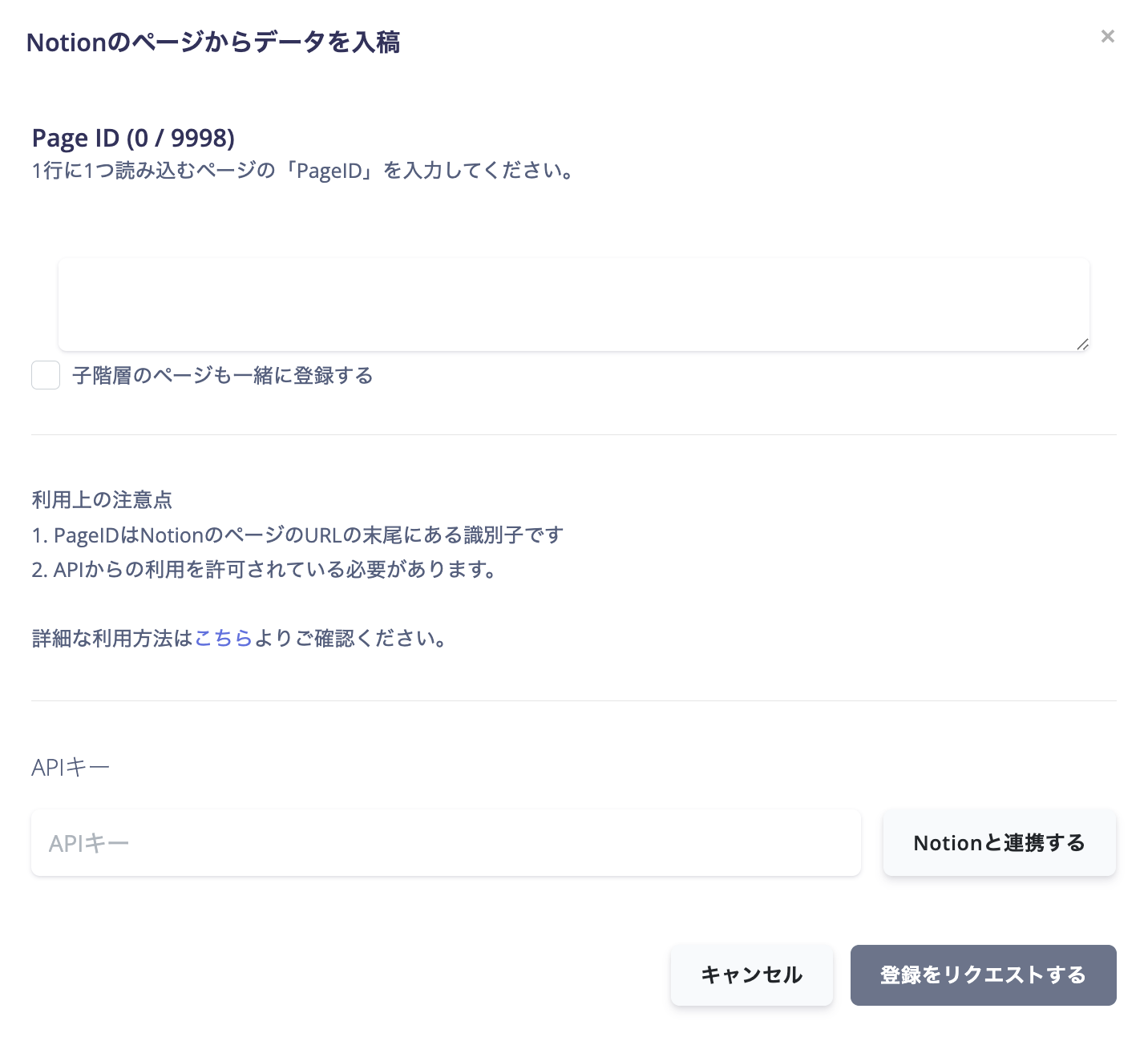
まずはNotionのAPIキーを登録しましょう。 Noitonの「インテグレーション設定」へ移動します。 <https://www.notion.so/profile/integrations>
インテグレーションを新たに作成します。

下記では「miibo-ナレッジデータストア連携」というインテグレーションを作成しています。 種類は「内部(インターナル)」を指定します。

シークレットキーが取得できるのでコピーし、Notion APIキーの欄にペーストします。
読み込むページの「コネクト」を設定する。 Notionページの右上にあるメニューから「コネクト」を選択します。

「接続先」の中から、先ほど用意したインテグレーションを選択します。
ここでインテグレーションを接続すると、miiboが設定したページのコンテンツを読み込めるようになります。
最後に、読み込むページのIDをURLの中からコピーします。

ページのIDはURLに含まれるページ固有の識別子です。
ページの種類によっては、URLにページのタイトルが含まれている場合があります。IDの部分のみコピーしてください。

ナレッジデータストアにページIDを登録することで、コンテンツがナレッジデータストアに追加されます。
API経由でデータをインポートする
API経由でナレッジデータストアにデータを登録することができます。
API仕様
API経由でデータを入稿する場合、以下の仕様に従ってください。 APIの仕様の詳細は下記のAPIリファレンスもご参照ください。
<https://miibo.readme.io/reference/add-datastore>
メソッド
PUT
エンドポイント
https://api-mebo.dev/datastore/create
JSON Bodyパラメータ
| パラメータ名 | 型 | 必須 | 説明 |
|---|---|---|---|
api_key | string | ○ | APIキーを指定します。公開設定画面でAPI連携を有効にすると取得できます。 |
agent_id | string | ○ | エージェントのIDを指定します。公開設定画面でAPI連携を有効にすると取得できます。 |
label | string | ○ | データのラベルを指定します。 |
text | string | ○ | データの本文を50,000文字以内で指定します。 |
url | string | データのソースとなるURLを指定します。 |
Curlサンプル
curl -X PUT -H "Content-Type: application/json" -d '{"agent_id":"<エージェントのID>","api_key":"<APIキー>","label":"<ラベル>","text":"<本文>"}' https://api-mebo.dev/datastore/create⚠APIリクエストを連続で行う場合は、必ず1秒以上のスリープ期間を設けてください。
APIキーの取得は 「外部サービスと連携する」 -> 「APIを利用する」 の画面にて、取得が可能です。